FLAG trains expressive flow policies for MaxEnt-RL through supervised target matching, rather than direct gradient-based policy optimization through the flow.
It replaces fragile global importance sampling with latent-conditioned local importance sampling, enabling scalable high-dimensional control and state-of-the-art performance.
From Global to Local Importance Sampling
Prior methods train diffusion- and flow-based policies by matching a target action distribution,
such as the unnormalized MaxEnt target exp(Q(s,a)/α). Since this target cannot be
sampled from directly, they use importance sampling (IS): sample actions from a proposal policy,
reweight them toward the target, and perform weighted score or flow matching.
The limitation is that IS can only reweight actions that were already sampled. When the
proposal-target discrepancy is large, especially in high-dimensional control, the proposal rarely
samples target-relevant actions. This yields sparse supervision and lead to failure mode.
Our key insight is to change where IS is performed. Prior methods use Global IS, which reweights samples over the full action space.
FLAG uses Local IS: it conditions both the proposal and target on the same flow latent variable z,
so reweighting happens inside a shared local region.
Local IS turns global target matching into local target matching
Global IS · prior work
Region
Full action space
Samples
Useful ones are rarely drawn
Supervision
Weak
Local IS · FLAG (ours)
Region
Local (latent-conditioned)
Samples
Even a few stay informative
Supervision
Dense
We first illustrate this effect in a controlled multi-goal task then show the same pattern in high-dimensional continuous control tasks in the Result section.
Multi-goal Environment (Didactic Experiment)
The multi-goal task isolates the small-sample regime: global-IS baselines fail when N≤8, while FLAG recovers the optimal multi-modal behavior with only N=2 samples.
Method
Q1Construct local IS?
Q1Construct local IS?
ChallengeSolutionLine
Challenge
Solution
Bottom
Line
Expand each Q card to follow the argument.
Q1–Q3 can be expanded; open a card to read its step-by-step reasoning.
Use the tabs: Challenge → Solution → Bottom Line.
Each tab is one stage of the answer — start with the problem, then the construction,
then the takeaway.
Challenge
→ Solution
→ Bottom Line
Q1How do we construct local IS, and is it consistent with the original MDP?
Challenge
For local IS to be principled — not just a trick — two conditions must hold:
Localization. The proposal and target distributions must share a region indexed by a latent z.
Consistency. Optimizing inside that local region must be the same optimization problem as optimizing the RL objective in the original MDP.
Without Consistency, local IS optimizes the wrong objective and any gains are illusory.
Solution
The deterministic flow map Tθ(s,z) transports a latent prior z∼pz to multi-modal anchor actions. Wrapping each anchor with a small Gaussian gives a tractable local density π^(a∣s,z).
The z-MDP augments each state with the latent z, giving a separate local policy π^(a∣s,z) per region. The red path shows local anchor generation from (s,z,θ); the blue path marginalizes over z to recover the global policy π(a∣s).
The z-MDP preserves both state–action marginals and the Q-function — optimizing on the z-MDP is the same problem as on the original MDP. Local IS becomes principled, not a heuristic.
Corollary 4.2 — Marginal consistency
ρπ(s,a)=∫ρ^π^(s,z,a)dz
Corollary 4.4 — Q-function consistency
Qπ^(s^,a)=Qπ(s,a),∀s,z,a
Full statements (Corollaries 4.2, 4.4) are in the paper. Details are in Appendix B.
Bottom Line
We construct the z-MDP, and prove that optimizing the RL objective on the z-MDP is equivalent to optimizing it on the original MDP (Consistency). Local IS becomes principled, not a heuristic.
Q2How do we incorporate this into MaxEnt-RL and update the policy?
Challenge
Two obstacles block plugging the z-MDP into MaxEnt-RL:
Intractable Entropy. The composite policy’s log-probability logπ(a∣s) requires marginalizing over the latent z — there is no closed form.
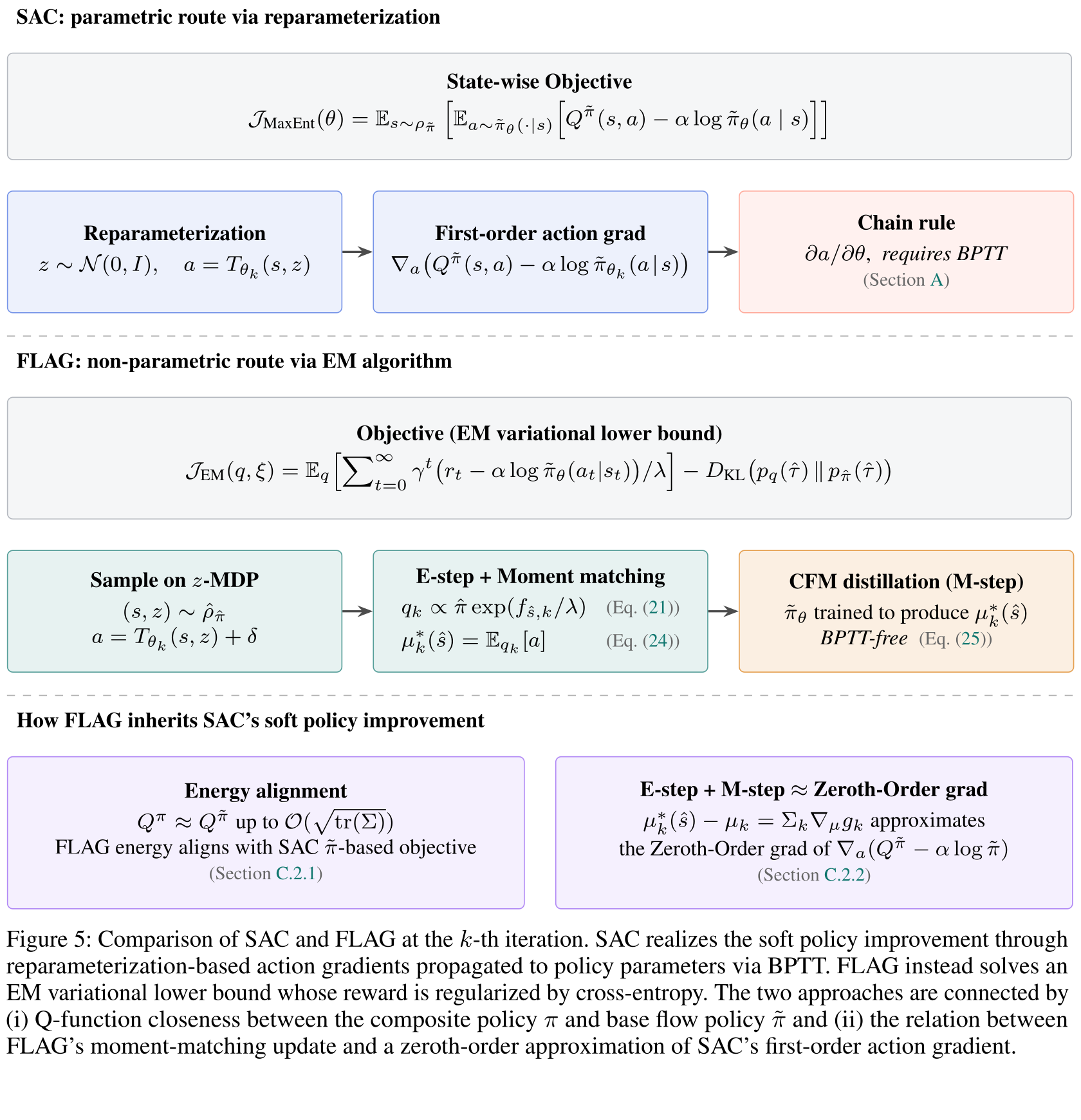
RL via Supervised Learning. We want to cast MaxEnt-RL as an EM algorithm whose policy update reduces to a supervised learning problem — avoiding backprop through the flow ODE (BPTT).
E-step — a local Boltzmann tilt of the Gaussian proposal around each anchor.
M-step — supervised regression of the flow onto improved action labels μk∗, using Method of moments to estimate the labels with N local samples.
Bottom Line
We use the cross-entropy as a tractable entropy surrogate and update the flow via an EM algorithm on the z-MDP — supervised distillation onto locally improved labels, not gradient-through-flow.
Q3Does FLAG provably improve the policy, and how does it relate to SAC?
Challenge
FLAG updates the policy by supervised distillation, not by differentiating the objective through the flow. Two guarantees are therefore not obvious — and this section establishes both:
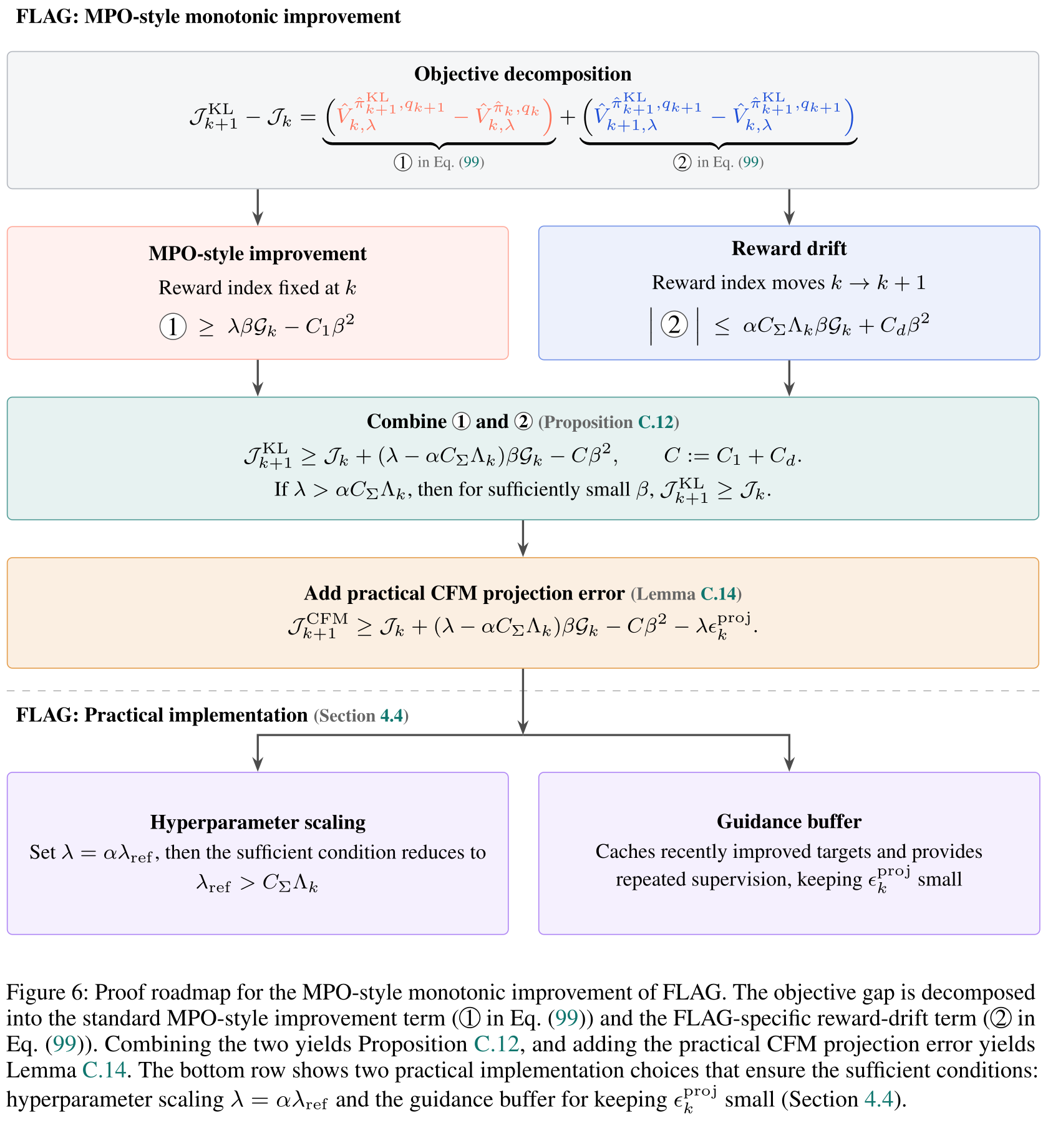
Monotonic improvement. Does FLAG’s update actually raise the objective, i.e. is Jk+1≥Jk guaranteed?
Relation to SAC. We optimize a MaxEnt-RL objective — so how does FLAG’s update relate to Soft Actor–Critic (SAC), and does it inherit SAC’s soft policy improvement?
One FLAG step splits into a positive MPO improvement term, a cross-entropy drift that scales with the local variance σk2, and the CFM projection errorϵkproj.
Whenever λ>αCΣσk2 and the projection error is small, the improvement term dominates, so Jk+1≥Jk — monotonic improvement.
SAC’s soft policy improvement theorem is agnostic to how the KL minimizer is obtained.
SAC restricts Π to a Gaussian and takes a first-order reparameterization gradient; FLAG solves the same KL minimization with a non-parametric, action-level update — a zeroth-order approximation via Stein’s identity and log-sum-exp smoothing.
Full statements and details are in Appendix C.2.
Proof Roadmap
Bottom Line
Monotonic improvement is established from two complementary perspectives — MPO (variational) and SAC (soft policy improvement) — and FLAG realizes SAC-style improvement for expressive flow policies without ever differentiating through the flow ODE.
Experimental Results
We present the results around the three questions used in Section 5 of the paper.
Q1Scale to high-dim actions?
Q1Scale to high-dim actions?
A1: Scalable & robust
Q1.1Scalable?
Click to expand
Expand each banner to reveal results.
Q1/Q2/Q3 cards and nested sub-banners (e.g., Q1.1) hide figures and tables until opened.
Click images to view detailed figure/table with caption.
Cards show clean caption-free previews; the enlarged view shows the original caption from the
paper.
Term used in experiments
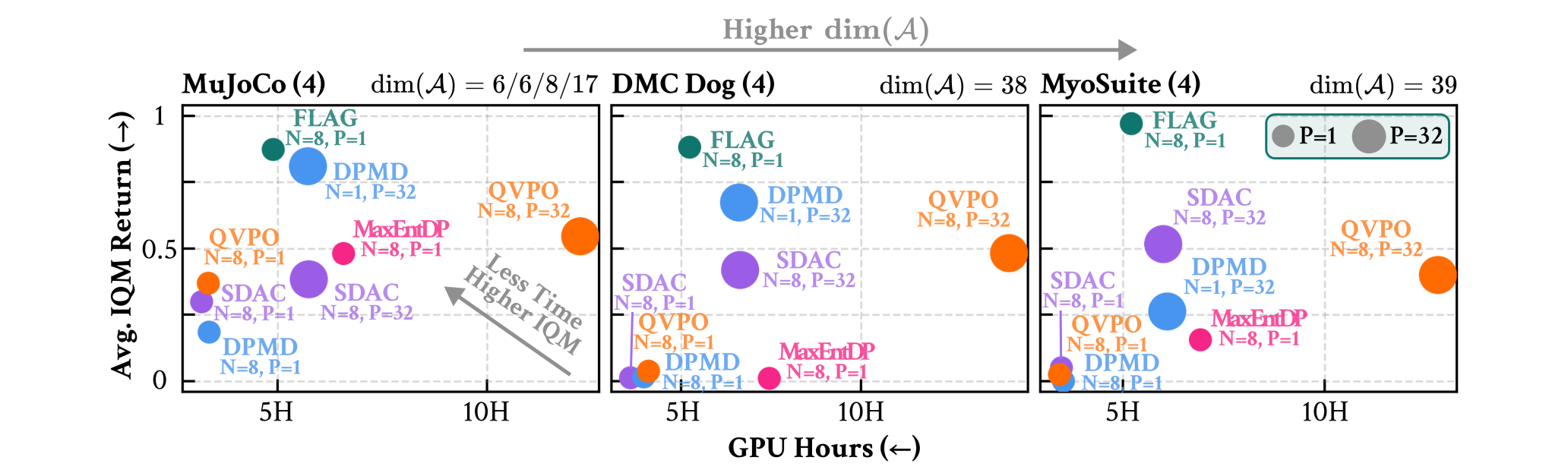
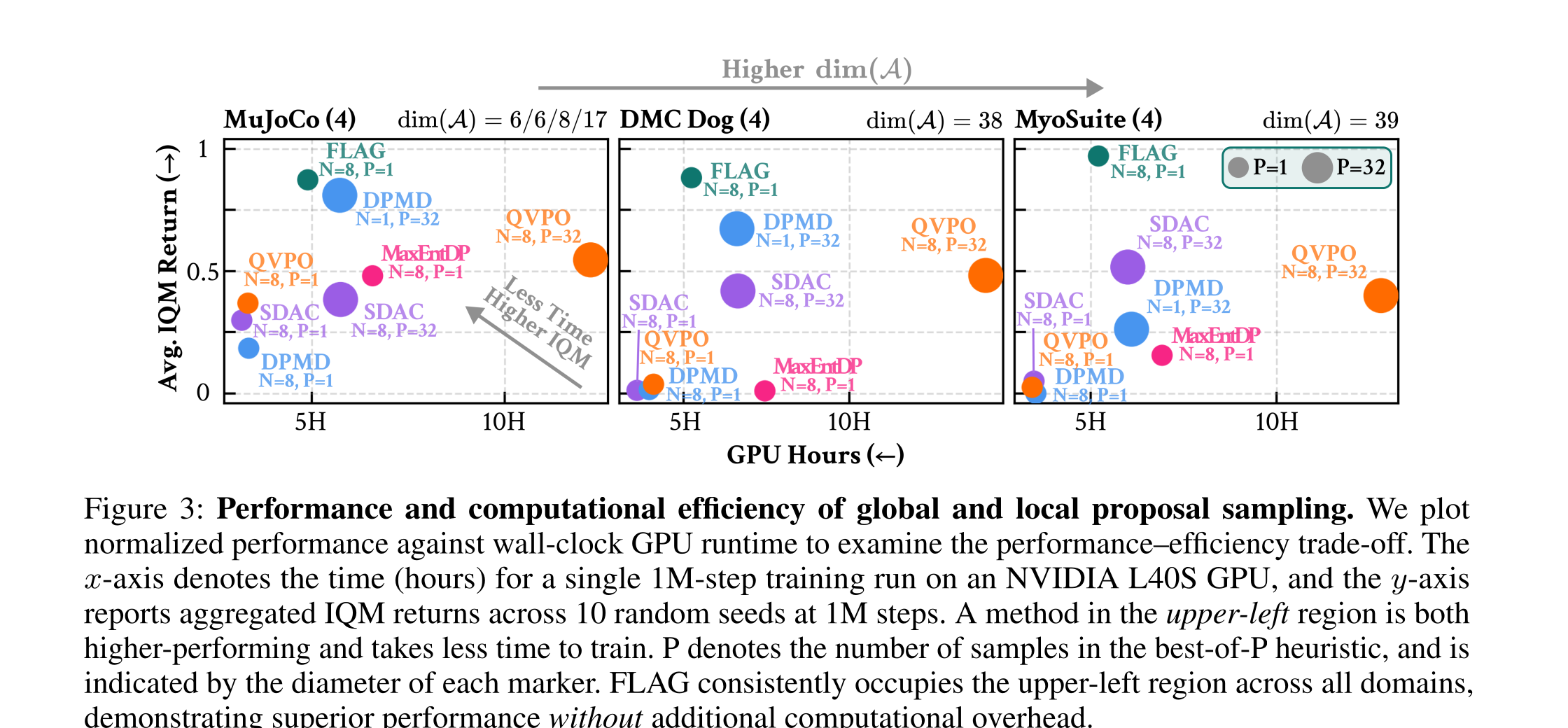
best-of-P: when sampling actions from the policy (e.g., during rollout and policy update), P candidate actions are drawn and the one with the highest Q-value is selected. FLAG excludes this heuristics, while other baselines heavily rely on this.
Q1Does FLAG scale to high-dimensional action spaces under limited sample budgets?
A1
FLAG is Scalable to High-dimensional Action Spaces and Robust to Sample Budget
Q1.1Is FLAG scalable to high-dimensional action spaces?
FLAG stays in the high-return, low-runtime region as action dimensionality increases, while global-proposal baselines degrade or require larger best-of-P budgets.
Q1.2Is FLAG robust to the sample budget?
Local proposal matching keeps importance samples informative even when the update uses only a small number of samples.
Learning curveLearning Curves
Q2How does FLAG compare to action-gradient and BPTT-based actor-critic methods?
A2
FLAG Outperforms BPTT-based Actor-Critic and Action Gradient Methods
Without CrossQ, critic gradients become less reliable.
FLAG remains effective because it aggregates critic signals into target actions rather than differentiating through the critic directly.
Q3How do our key design choices---covariance scheduling and the guidance buffer---connect to the theoretical results?
A3
FLAG Key Design Choices Align with Theoretical Results